








Warehouse-First Marketing: What it is and Why It’s Replacing the Traditional Data Stack

The way brands think about data has shifted significantly over the past few years. For most of the last decade, the focus was on collecting as much data as possible. The assumption was simple: more data meant better decisions.
But marketers have spent years trying to draw actionable insight from fragmented customer data spread across siloed tools, and the volume hasn’t helped. Unless data is accessible and usable in the moment, it doesn’t drive better experiences. It just creates more noise.
Rather than adding yet another tool to fix the problem, forward-thinking brands are re-evaluating their entire stack. And increasingly, the answer requires tapping into the single source of truth: their data warehouse.
From Passive Repository to Active Source of Truth
Data warehouses aren’t new. Traditionally, businesses relied on on-premise warehouses that are powerful, but often rigid, expensive to scale, and siloed from the teams that needed the data most.
The shift happened with cloud data warehouses such as Snowflake, Google BigQuery, Databricks, Amazon Redshift, and Azure Synapse. These platforms changed what a warehouse could do. Suddenly, you had infrastructure that could handle vast, growing datasets without heavy upfront investment, integrate data from sales, finance, marketing, and customer support in one place, process complex queries fast, and give different teams access with appropriate governance controls.
Cloud data warehouses offer consumer brands the following advantages:
- Scalability: Easily handle vast and growing datasets without massive upfront infrastructure investment.
- Flexibility: Integrate structured and semi-structured data from teams like sales, customer support, finance, marketing, etc.
- Performance: Process complex queries rapidly, enabling faster insights.
- Accessibility: Democratize data access for various teams (with appropriate governance).
The result: data warehouses stopped being passive repositories and became the most complete, up-to-date, and trustworthy view of the business. The question forward-thinking teams are now asking is: why does their marketing activation still run on a copy of that data rather than the source itself?
That’s what warehouse-native marketing is trying to solve.
How the Modern Data Stack Created a New Kind of Silo
The traditional marketing stack was built in layers with each one designed to solve a specific problem, and each one adding cost and complexity in the process.
It looks like this:
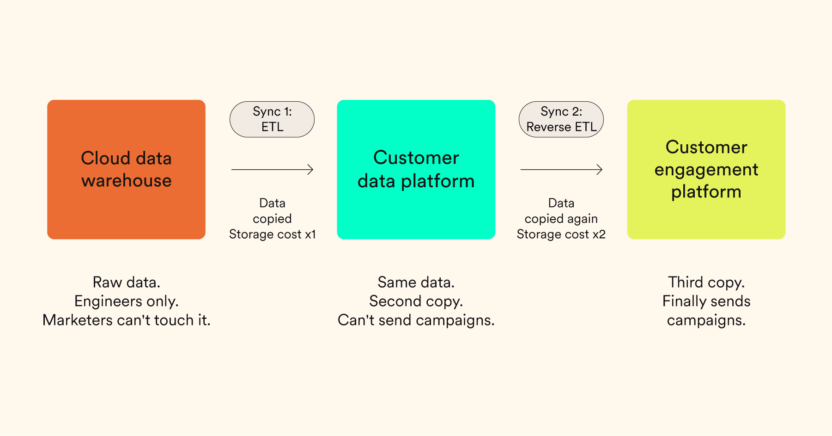
Three separate tools. Two syncs. The same data is stored three times. The side-effects are hours of latency, triple the storage cost, and data movement across multiple vendors.
Layer 1: The Cloud Data Warehouse The warehouse acts as the company’s central backend archive storing raw data from apps, websites, and offline stores. It’s managed by data engineers, not marketers. The data here is complete, accurate, and governed. But it isn’t directly accessible to the marketing team.
Layer 2: The Customer Data Platform To use the data, the marketing team purchases a separate CDP. Data engineers build pipelines to copy raw data from the warehouse into the CDP. The CDP cleans this copied data to create unified user profiles. The result: the same data now lives in two places, with its own schema, its own identity model, and its own sync relationships that need constant maintenance.
Layer 3: The Customer Engagement Platform The CDP itself can’t send emails, SMS, or push notifications. So the marketing team purchases a third tool – Customer Engagement Platform. Marketers use reverse ETL tools to copy unified profiles from the CDP into the CEP database. The same data now lives in three places.
A clear example of this problem is a meal kit company profiled in a 2026 analysis that had customer data spread across six systems, each holding its own copy of customer profiles synchronized through a network of API integrations. The engineering team’s audit found that 12% of customer profiles had conflicting attribute values across systems, and sync latency ranged from 15 minutes to 24 hours depending on data type. This wasn’t an unusual implementation but a predictable outcome of the copy-and-sync architecture the traditional stack requires.

Think of it this way.
In the traditional approach, a restaurant stores its ingredients in a massive warehouse across town. To cook a meal, an assistant packs up the ingredients, drives them to a prep kitchen (CDP) to wash and chop them, then packs them up again and drives them to the final restaurant kitchen (CEP) where the chef can plate the dish. By the time the food reaches the customer, it’s cold and you’ve paid for three separate kitchen rents and two delivery drivers.
Why this setup fails:
- Data lag. Copying data through three separate systems takes hours or days. By the time a segment reaches your engagement platform, the customer’s behavior has already changed.
- High cost. Vendors charge based on how many data points you copy and store. Three platforms mean three storage bills for the same data.
- Security risk. Moving sensitive customer data across multiple platforms increases compliance vulnerabilities. Every handoff is a potential exposure point.
- Engineering dependency. Maintaining the pipelines between these three systems is a full-time job for data engineering teams time that doesn’t go toward building better experiences.
What Warehouse-First Marketing Actually Means
Warehouse-first marketing puts the data warehouse at the center of the marketing stack. Basically, it is not acting as a passive analytics repository, but as the active source of truth for segmentation, audience building, personalization, and campaign activation.
All customer profiles, behavioral data, transaction history, product usage, and support interactions live in one place: the warehouse. Marketing tools don’t need to ingest copies of that data. Instead, they query it in place, using the warehouse’s compute and governance rules.
The warehouse-native approach is the chef walking straight into the warehouse, where the ingredients are already fresh, prepped, and clean, all he needs to do is cook and serve the meal right there on the spot. No driving. No extra rent. No cold food.
Benefits of the Warehouse-First Approach for Your Team
Warehouse-first marketing doesn’t just consolidate your data, but changes what your marketing team can do with it. Here’s what it unlocks:
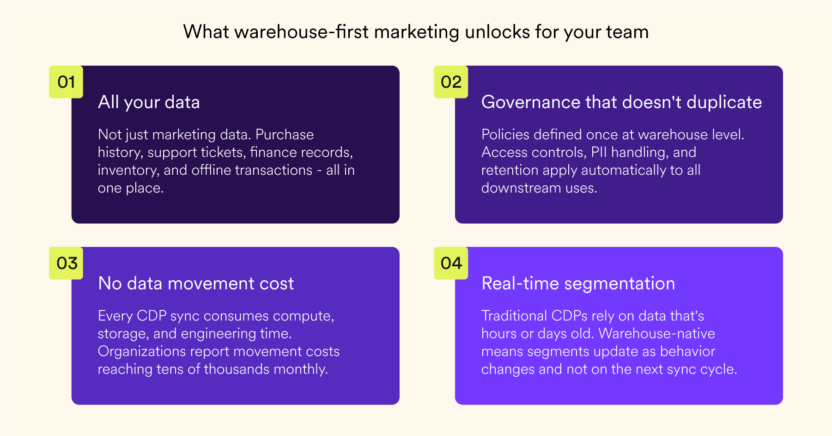
These aren’t incremental improvements. But they’re what becomes possible when your marketing stack stops treating the warehouse as a backend system and starts treating it as the engine.

Is Your Stack Ready for Warehouse-First Marketing?
Warehouse-first architecture works best when certain foundations are already in place such as a governed cloud data warehouse, clean data models, and a team comfortable working with warehouse infrastructure. If those are in place, the payoff is immediate: no data movement costs, no sync latency, no governance duplication.
If you’re not there yet, that’s not a blocker. MoEngage meets you where you are. For brands that haven’t yet built mature warehouse infrastructure, data can be ingested directly into MoEngage through Data APIs, SDK integrations, or CSV file imports. This gives you a fully functional engagement and analytics stack while your data infrastructure matures. As your warehouse investment grows, warehouse-native capabilities activate on top of what’s already in place. You don’t have to wait to get started.
CDEP as Warehouse-First Approach for Marketing Teams
Forward-thinking consumer brands have realized that customer data management and customer engagement cannot exist in silos.
This is how a data-driven marketer is thinking:
|
The gap between raw warehouse infrastructure and marketing-ready activation is exactly where the CDEP model operates.
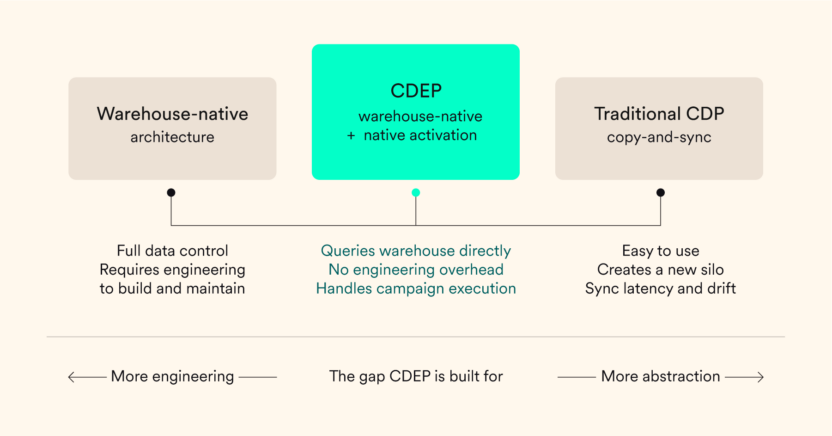
A Customer Data and Engagement Platform connects directly to the warehouse without requiring a full reverse ETL pipeline, while also handling campaign execution natively. For marketing teams at organizations with an existing Snowflake or BigQuery investment, warehouse data becomes available for segmentation and personalization without a data engineering sprint for every new use case.
Unlike a standalone CDP that creates another copy of your data, or a reverse ETL tool that syncs segments on a batch schedule, a warehouse-native CDEP reads from the warehouse directly so the data your marketers act on is the same data your data engineers trust. One source of truth. No handoffs. No drift.
What Makes MoEngage the Right Warehouse-Native CDEP?
MoEngage solves this through three native capabilities.
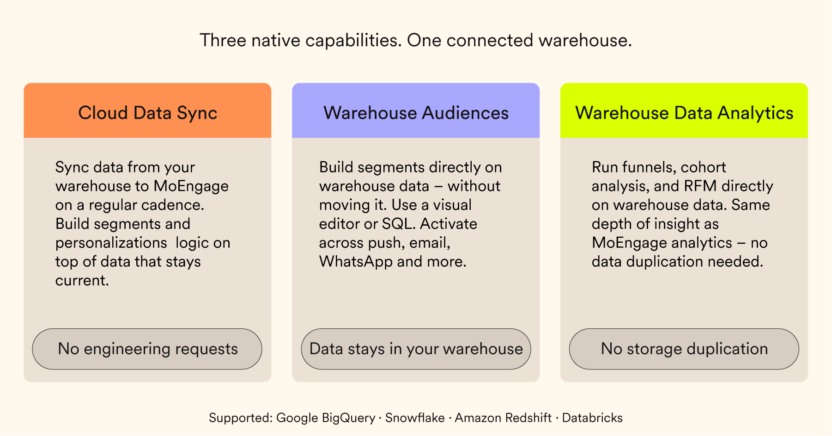
Most warehouse-native tools still require a separate engagement platform to fully activate the data. MoEngage is different. It’s a single platform that acts as your warehouse-native data layer, your analytics engine, and your customer engagement platform – all in one. Your data ingestion, unification, identity resolution, AI decisioning, and campaign execution happen inside the same system. No separate warehouse tool. No CDP sitting in the middle. No reverse ETL pipeline maintains the connection between them. The data your marketers use to build segments and personalize campaigns is the same your data team trusts because it’s coming from the same place, processed by the same platform, and activated in the same system.
Warehouse Segments
Warehouse Audiences lets marketers build segments directly on warehouse data without moving it to MoEngage. Once you connect your warehouse, you get a clear view of your data schema (tables, columns, logic) and a visual editor to build your audience without writing a single line of SQL. MoEngage generates the query on your behalf and syncs the audience for activation across any channel (push, email, WhatsApp, and more). For teams that prefer full control, a SQL editor is also available. This capability is particularly valuable for brands with sensitive transactional data, high-volume event datasets, or strict data residency requirements where moving data off the warehouse isn’t an option.
Warehouse Analytics (Upcoming)
Warehouse Analytics will bring MoEngage’s full analytics capabilities, such as funnels, cohort analysis, and RFM, directly to the data sitting in your warehouse. The same depth of behavioral analysis marketers run on MoEngage data will be available on warehouse data, without duplicating storage or compromising governance.
Cloud Data Sync
Cloud Data Sync lets brands sync data directly from their warehouse to MoEngage on a regular cadence. No data team requests, no waiting for exports. Segments and personalization logic are built on top of warehouse data that stays current, and MoEngage handles all observability and monitoring, keeping operational overhead low.
MoEngage currently supports Google BigQuery, Snowflake, Amazon Redshift, and Databricks.
Conclusion
Warehouse-first marketing isn’t a trend. It’s a response to a structural problem that’s been compounding for years — customer data living in one system, marketing activation happening in another, and the gap between them eating into relevance, budget, and ROI.
The brands moving fastest right now aren’t the ones with the most data. They’re the ones whose marketing stack can actually use it without copying it, waiting for it to sync, or filing a request every time a new metric is needed.
If your data warehouse is already the most complete, accurate view of your customers, the question worth asking is simple: why isn’t your engagement platform reading directly from it?
Talk to our team to see how MoEngage connects to your warehouse and what that means for your marketing activation.






