








Elasticsearch – Now And Then (Part 1)
At MoEngage, there are quite a few data systems. These are the backbone of the pipeline that processes more than a billion user events per day. The king of them all is elasticsearch – which is our primary storage for user activity as well as user profiles.
Elasticsearch has been used at MoEngage since its beginning. Over the last 3 years, we have struggled, hacked and formalized a lot around elasticsearch. And it has made things smooth for us. We have been running without any glitches for the past 1 year.
Today, we are going to share bits and pieces out of our journey with elasticsearch (from 1.4 -> 1.7 -> 2.2). Though we have divided this journey into two parts, this is going to be a bit long. So better grab some coffee before moving ahead.
The Stone Age
At MoEngage, we refer to the elasticsearch 1.4 era as the STONE AGE. Why Stone Age? you will know soon.
Those were the early days for MoEngage. With the booming client base, more and more data was coming into the system. In the middle of this growth phase, every day, there would be someone screaming in the office –
ES is down! AGAIN!
It became so frustrating that we felt like throwing a stone at it. Hence the stone age. It was OUR problem. We had to get out of the firefighting mode with some concrete solution. We began by analyzing a few of our outages. We discovered few patterns which looked random but were repeating over time:
- JVM Long GC Pauses – experienced on various nodes at various times.
- Index Creations Failing – caused by unresponsive master nodes.
- Node Left Cluster – One node leaves and sends the cluster into a whirlpool of crashing nodes.
- Indexing Queues – on nodes causing OOM errors and slowed ingestions.
- Cluster Split Brain – One master became unresponsive causing a split brain to the rest of the cluster.
Reality Check – The Good, The Bad And The Ugly
After further analyzing our design, we discovered a few flaws (read blunders)
-
The Good – we were able to serve our client traffic and ensure business continuity.
-
The Bad – we were not sure how long we could continue in this firefighting mode.
-
The Ugly – our team had to spend hours and hours daily to ensure system uptime with a lot of manual effort.
The problem was an inherent one; it arises with the flexibility of tracking events. Customers can track any user activity within their app.
For instance, an e-commerce company might want to track `added_to_cart` or `product_purchased` as an event.
In elasticsearch, each of these events is saved in their own elasticsearch indexes. This framework worked well, but only until we had a limited number of unique events. And different clients tracked a limited amount of data per event. (The complexity here would be – N customers each tracking M unique events would create N x M unique ES indexes).
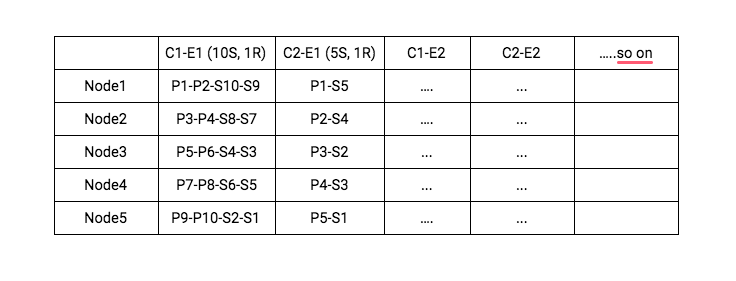 Here C1-E1 is an index with 10 shards and 1 replica each, while C2-E1 is an index with 5 shards and 1 replica each. We were serving hundreds of clients at that moment, each tracking hundreds of events. We had indexes and shards in the order of >10k already (at a much smaller scale compared to today). And the index count was growing day by day.
Here C1-E1 is an index with 10 shards and 1 replica each, while C2-E1 is an index with 5 shards and 1 replica each. We were serving hundreds of clients at that moment, each tracking hundreds of events. We had indexes and shards in the order of >10k already (at a much smaller scale compared to today). And the index count was growing day by day.
-
Index creations were taxing operations in the elasticsearch. It needed a full cluster state update across each node in the cluster. These were much more frequent for us.
-
Aggregation queries are very memory intensive and need dedicated nodes to run. Our aggregation queries used to run on data nodes, causing frequent OOM crashes.
-
Cluster recovery is very slow when shards are either huge, or small and many
-
Larger the shard, higher the time is taken to ingest more documents into it.
-
Queries on larger indexes can cause the nodes to get stuck in indefinite GC loops
-
Stuck nodes can make the master node unresponsive if master node is waiting for an acknowledgment from that node (elasticsearch bug in v1.4.4)
-
Indexes are immutable in elasticsearch, making it impossible to scale an existing index. We were reading and writing to the INDEX NAME rather than an alias, preventing us from scaling over time.
-
Indexing queues can cause too many threads to spawn at the nodes. This causes high ingestion latencies and node instabilities.
How we figured out to erase all these issues? What are the solutions adopted by MoEngage to fight the Bad and Ugly scenarios? Answers to these questions are waiting for you in the next installment of this blog.Here is the good news, the second part covering the solutions is now available here.
| Here’s What You Can Read Next: |






