







Elasticsearch – Now And Then (Part 2)

Bonus Content:
|
In the first part (you can read it here), of this two-part blog series, we discussed the challenges of using Elasticsearch with a growing database at MoEngage. Continuing the journey in this part, we’ve included the solutions and practices that helped us overcome challenges and run smooth operations.
The Remedy
It was a two-step process.
First, we upgraded our cluster to ES 1.7.4. It was a breakthrough for us as it fixed quite a few issues related to metadata management. We weren’t ready for a major upgrade as it would need application changes. This allowed us some breathing space to plan the next steps. We had to overhaul the entire system to prepare for the future.
Second, we listed down must-have capabilities in the new event storage. Based on these requirements, we started redesigning our data storage.
Here is a bird’s-eye view of the data storage requirements:
- Data Retention: We couldn’t store complete data for all clients since our start. We needed some retention policy on the data in the cluster.
- Data Backup: We needed to enable continuous data backups to ensure data recovery in the event of unforeseen system breakdown.
- Quicker Recovery: We could not afford long downtimes anymore. In cases of unavoidable downtime, we had to recover as quickly as possible.
- Metadata BlowUp Protection: We needed protection from random bursts of metadata updates issued to Elasticsearch. These bursts disrupt the cluster many times.
- DataType Handling: Elasticsearch isn’t truly a schemaless system. It automatically detects schema. However, we did face challenges at times due to data-type mismatch. We resolved this via datatype namespacing (prefix datatype to attribute name).
- Multi-tenancy: We were adding more clients every day. Each one was coming with custom requirements. We needed to have adequate bandwidth to separately sustain the operations, if required, for some of the P0 clients.
- Monitoring: We needed close monitoring at multiple levels to ensure no data loss and perfect query execution. Even the slightest impact to the cluster stability needed to be detected and acted upon.
- Load Distribution: We needed to efficiently use the available resources to distribute the read and write load, in order to allow horizontal scaling.
Here is what we did to handle most of the above requirements:
- Multi-tier Design: All the smaller client accounts grouped and larger ones handled separately.
- Volume/Size Based Indexes: Indexes created based on expected data volumes generated by a client instead of using the older client-action based system.
- Weekly Rolled Data Storage: The data storage (indexes and shards) rolled out every week, allowing us the flexibility to scale up/scale down certain tiers.
- Alias-basedReads/Writes: The system transitioned to perform operations on aliases instead of index names, giving us the control over reads and writes.
- Client Nodes for Aggregations: All aggregation queries moved out to Elasticsearch client nodes. It helped the core data storage layer to stay stable.
The new system topology looked as below:
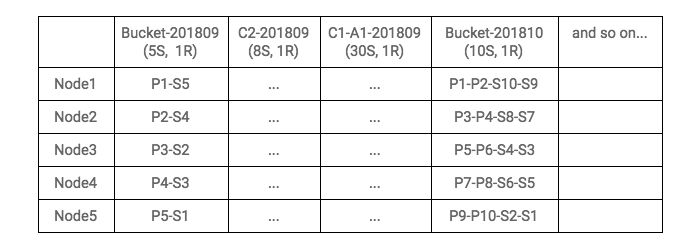
Here, each bucket index (Bucket-201809, Bucket-201810, and so on) stores events for multiple clients. Each contains thousands of aliases in it, while a client level index (C2-201809) would have a few hundred aliases (one for each client event). We also added event level indexes (C1-A1-201809). This reduced our cluster metadata volume and cluster update operations dramatically.
This architecture gives us the flexibility of load distribution and traffic routing (as aliases could be easily moved).
Lessons Learnt
- Storage systems are complex and display unique behavior.
- Documentation is your best friend. It is advisable to read the entire documentation at-least twice before deploying a new storage system to production.
- Requirement analysis is very important. What are we expecting out of our systems? Hint: Apply CAP theorem.
- Leverage best practices from the maintainers of the database. Most database systems publish blogs about their recommendations and production tweaks. They can be helpful when you need help with implementation and bug fixing.
- Monitor and then keep monitoring everything.
- Data systems depend a lot on data schema. A bad schema can bring the best of systems down on their knees.
- Load distribution is crucial as it can severely impact system performance.
Today, we run multiple Elasticsearch clusters, with hundreds of nodes that store terabytes of data ingested at the rate of 30-40K docs per second at peak-time while maintaining almost 1M field mappings (which is huge for Elasticsearch). However, this wouldn’t be possible without implementing the above best practices. These steps have ensured that our platform evolves simultaneously with our growth, enabling us to deliver uninterrupted services to our global clients confidently.
We would love to hear your thoughts too. Got views, questions or experiences to share? Post them in the comments section below or reach us at [email protected]. If you’re interested in joining our team of marketing enthusiasts and technology specialists, take a look at the job openings at MoEngage here.






