








Reduce Production Bugs by Automating Tests and Code Reviews

Bonus Content:
|
“The Right message to the Right user at the Right time.” – MoEngage
That’s a lot of “Right” but achieving this mission statement is possible only when we focus on the fourth R – Reliability. In fact, reliability features as the topmost item on the checklist during enterprise software adoption.
A minor oversight or a bug in the code could potentially cost thousands of dollars in damage & reputation to clients. It is, therefore, essential for companies to maintain a healthy codebase through the proper implementation of coding and testing techniques.
In this post, we take a deep dive into our in-house Code Testing and Automation Solution that enables us to maintain a healthy codebase and deliver reliable and world-class products.
Background
In the early days of MoEngage, we had a monolithic codebase with 0% test coverage. Almost all the code was new, and we faced little to no issues, allowing us the freedom to explore possibilities and build features.
Fast forward a couple of years and the codebase has transformed rapidly. The transformation is partly due to adding more depth to the existing features and the addition of new features. However, the development came at a cost – Reliability. As the codebase grew, clients gradually started facing issues, affecting their business.
The Case for Test Cases

Image by Geek & Poke
Upon conducting an RCA (Root Cause Analysis) of the client issues, one thing that frequently popped up was the lack of ‘Test Cases.’
Our team decided that writing ‘Test Cases’ would be an excellent strategy to maintain the code quality.
A test case is a set of conditions or variables under which a tester or a testing software will determine whether a system under test satisfies requirements or works correctly. The process of developing test cases can also help find problems in the requirements or design of an application.
But a test case strategy had its own set of challenges:
- How do we write the test cases for the older lines of code?
- Who is the right person for this job?
- Is it worth sacrificing the pace of product development and fall short of customer expectations concerning product features?
These are some of the questions that hit us. But product reliability (remember the fourth R? :)) was equally or more important than product features, and we proceeded with writing the Test Cases.
Did it work?
“Good intentions never work, you need good mechanisms to make anything happen.” – Jeff Bezos, CEO, Amazon.
At first, we sought out the easy solution and announced to the team that, any new code should have the unit tests covering all the facets of the code and always remember that the test cases are pillars of reliability.
However, after two months, we realized there were not enough test cases, and the problems persisted. Hence we decided to build an automated mechanism to not only encourage more unit tests but also to ensure the tests covered all the use cases.
Problem statement
1. Design a sound mechanism that ensures
- No new code ships without proper test coverage.
- Tests should cover most of the important business logic.
2. Devise an automated system that facilitates the above mechanism.
As we took a deep dive into building the automation system, we were faced with more granular issues:
- How do we interrupt a PR (Pull Request) to perform the checks? (A pull request merges the fresh lines of code with the existing codebase.)
- Where do we perform these checks?
- How do we identify the new lines of code?
- How do we check if the new lines are covered in the unit tests?
- How do we block the PR, which doesn’t meet the criteria?
- What would call this mechanism? (Naming is important to us :))
The Solution
Following are the details of our experience in solving the above problems. But first, a big thanks to our Quality Automation Lead Pooja for building this amazing system single-handedly within a short period.
The solution, christened SHIELD took us two weeks to build. SHIELD ensures that no new code is merged unless it satisfies the following checks:
- Syntax Validations
- Compilation Success
- Critical Use Cases Coverage (Sufficient Test Coverage)
Upon failure of any one of the above checks, SHIELD blocks the pull request (the process for merging new lines of code with the existing ones). Here’s how SHIELD works:
Interrupting PR – We maintain our codebase on GitHub, and we found that there is a callback/webhook feature available on GitHub when a PR is raised.
Jenkins Server – We have redirected the webhook to our Jenkins server, where a customized job is run to handle this request.
New Lines – As you know, a PR may contain added or deleted lines, so we wrote a custom script to identify how many lines were added along with the line numbers.
Comparison – We have used nose to run tests along with coverage library plugin, to find out the coverage stats for our code, as part of this, nose provides us with the information on how much coverage a file has and also which lines are covered and which aren’t.
Validate PR – Every PR that is raised in the system has to go through a pylint check and a test coverage check. The PR is blocked if pylint reports any bug or if the Test Coverage for the newly added lines is less than 85%.
The nitty-gritty: After pulling the line numbers for the new lines in the PR, we compare them with the respective reports and assert the state of PR. This minor tweak helped us improve the test coverage for the new code and address the challenges.
Block PR – GitHub, provides more APIs to interact with a given PR after we confirm if a PR is valid or not, we update the status of the PR accordingly. This (image below) is what a failed PR looks like. As you can see, the ‘Merge’ button is blocked/ unhighlighted.
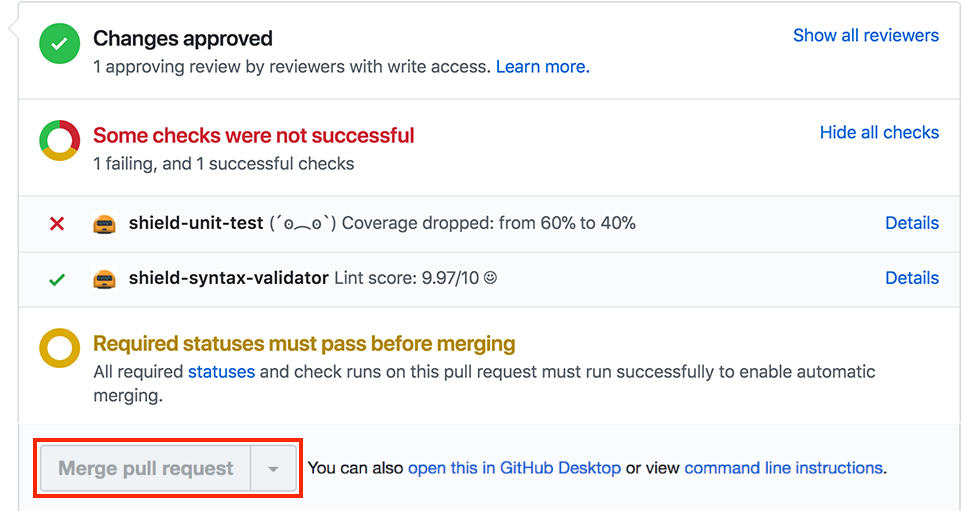
Once the checks pass, decent confidence is built. However, a strict peer Code Review is still required to merge the PR.
Name – After a lot of thought, we agreed that we would name the mechanism as SHIELD (Inspector is the other name that came close).
The Result
Thanks to SHIELD, we were able to increase the codebase test coverage to 56%, within a short period. This boosted our confidence in continuous integration across all features and also helped us in significantly reducing the production bugs.
SHIELD, however useful it is, is not a replacement for humans. The code quality ultimately lies with the person who is reviewing the PR, but a little automation can go a long way in ensuring a better quality of code. SHIELD boosted the reliability of our overall codebase and most importantly reduce the problems faced by the clients to a large extent.






