







How MoEngage Ensures Real-time Data Ingestion for Its Customers

Why Is Real-time Data Ingestion Important for B2C Brands?
MoEngage is an enterprise SaaS business that helps B2C brands gather valuable insights from their customer’s behavior and use these insights to set up efficient engagement and retention campaigns.
As these campaigns and insights are based on the end users’ interactions (consumers), the most critical requirement is to be able to ingest all of this demographic and interaction data and make it available to various internal services in a timely fashion.
As the business has grown over the last years, we have been fortunate to be able to help customers across the world to achieve their marketing goals. With businesses becoming increasingly digitized, our customers themselves have seen growth in their customer base at an exponential rate. They have now come to expect highly responsive applications, which can only be possible if their data can be ingested in real-time.
What High-level Approach Did We Take to Solve This?
MoEngage tracks around 1.2 Billion monthly active users and 200+ billion events from our customers every month. Given the scale and diversity of the customers, processing the data in the real time isn’t just about the speed, it’s also about how economically we can do it. During our data processing, the main challenge starts with how we scale the writes. We have set ourselves a daunting goal of ensuring data availability within 5 seconds.
One of the techniques that can dramatically improve the scale of writes is the use of bulk writes. However, using it is tricky as any consumer’s activity is coming on the fly, and processing its data requires access to its latest state for us to be able to do consistent updates. Thus to be able to leverage it, we need a messaging layer that allows partitioning data in a way that any given consumer’s data would always get processed by only one data processor. To do that as well as achieve our goal of ordered data processing, we decided to opt for Kafka as a pub-sub layer. Kafka is a well-known pub-sub layer that among other things, supports key features such as transactions, high throughput, persistent ordering, horizontal scalability, and schema registry that are vital to our ability to scale and evolve our use cases.

MoEngage’s real-time data ingestion helps brands deliver personalized messages to their customers at the right time
The next bit of insight was that in order to leverage bulk writes, rather than using the database as a source of truth, we needed a fast caching layer as a source of truth allowing us to update our databases in bulk. Our experience with DynamoDB & ElastiCache (redis) taught us that this would be prohibitively expensive. For this reason, the caching layer that we would use would have to be an in-memory cache. This would not only lower the cost of running the cache but would lead to large gains in performance as well. The most prominent key-value store for this use case is RocksDB which can leverage both the memory of an instance as well as its disk should the amount of data stored overflow the memory.
Our decision to use RocksDB and Kafka introduces new challenges as what used to be a stateless system would now become a stateful application. Firstly, the size of this RocksDB cache would be in the order of hundreds of gigabytes per deployment, and the application leveraging it could restart due to various reasons – new feature releases, instance termination by the cloud provider, and stability issues with the application itself. The only way to reliably run our application would be to track the offsets at which we last read data from Kafka and keep that in alignment with the state of the contents of our cache. This aggregated state would need to be persisted externally to allow for recovery during planned or unplanned restarts. Above all, we would need a high level of configurability for this entire checkpoint process (frequency, the gap between checkpoints, concurrent checkpoints, etc.). Rather than building the entire solution in-house, it was more prudent to leverage existing frameworks as they would have better performance, reliability and community support.
Enter Apache Flink, we evaluated various streaming frameworks and concluded that Apache Flink would be the one with all the features and the desired performance at our scale. At a high level, a flink job consists of one or more task managers who are responsible for executing various operators that implement the data processing requirements of the application. The job of allocating tasks to task managers, tracking their health, and triggering checkpoints are handled by a separate set of processes called job managers. Once the task managers resume data processing, any user state gets stored in a finely tuned RocksDB storage engine which gets periodically checkpointed to S3 and Zookeeper in order to facilitate graceful restarts.
How Did We Put It All Together?
After figuring out the right language, framework, and messaging layers, the time came to start building out the system and migrating all our existing features. Our ingestion layer consists of 4 steps:
- Data validation layer that intercepts customer data via various sources
- Internal schema management and limits enforcement for all the user, device, and events and their properties that are tracked across customers as well as customer-specific properties
- Using the identifiers in the incoming requests to fetch, possibly create and finally update the state of users and their devices
- Enriching the incoming interactions that were performed by an end user with details about the user that we internally store about them and making them available to other services
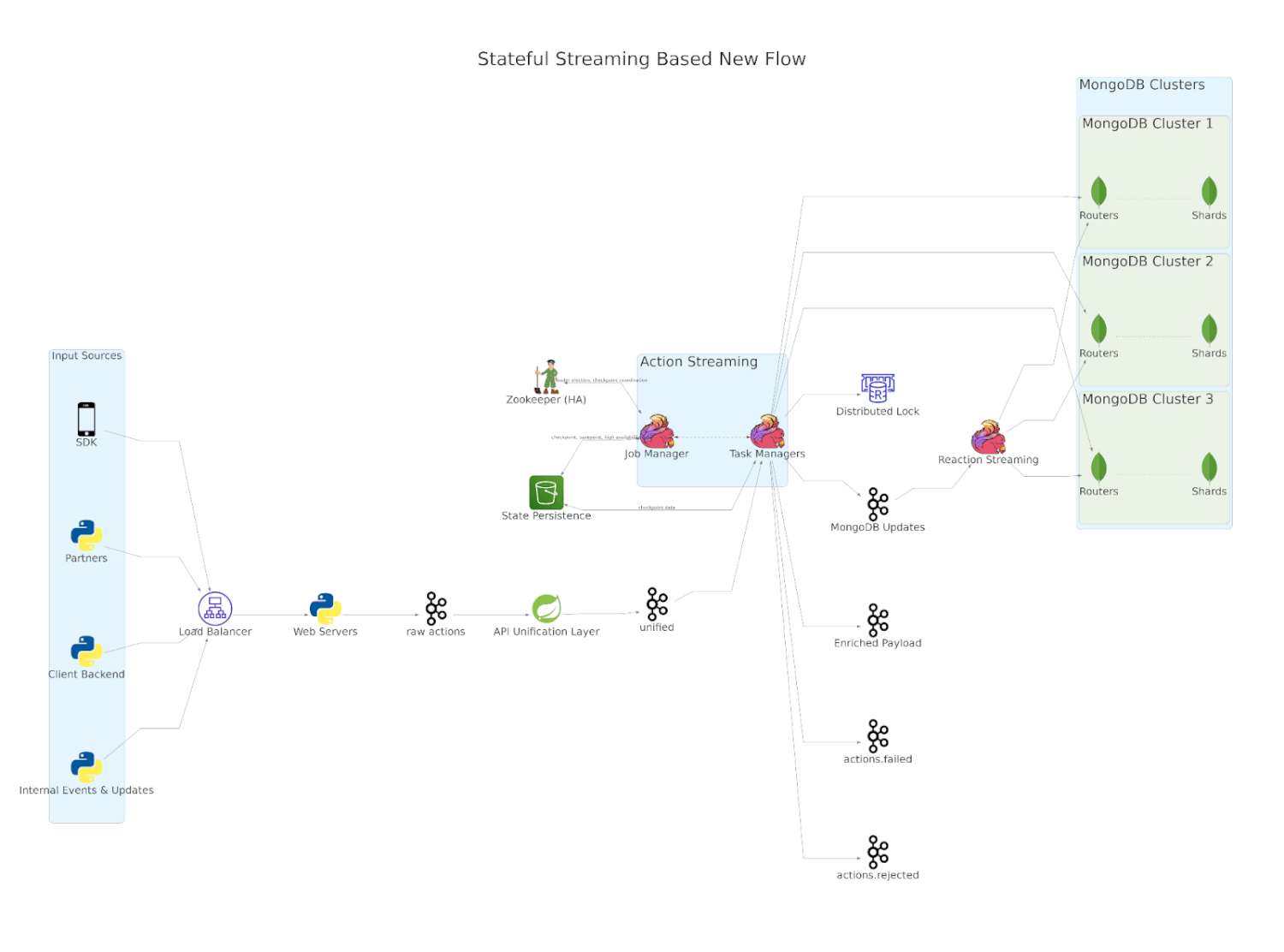
Let’s discuss the important layers and what each of them do.
API Unification Layer
As data validation and schema management aren’t really tied to any particular user but rather to a client, we decided to carve these features out as a dedicated service. Additionally, as we mentioned earlier, data can come from various sources including mobile SDKs that we provide, data api to publish the same via the clients’ backend, third party partners such as Segment, ad attribution services, CSV files and internal apis. As each of these were targeting different use cases, over the years, the implementations for ingesting data across these sources had diverged even though the ultimate goal was to update the state of users and their devices. We took this opportunity to consolidate the behavior across sources within this data validation layer and transform each of these inputs into one consolidated output stream that could serve as input to services that implement the rest of the functionality.
Action Streaming
The most critical service is the one that deals with user & device creation as well as event processing. With data validation and api variations taken care of in the upstream layer, this service relies on the identifiers of users and devices in the consolidated payload to determine what user and device that might have been involved, which might sometimes involve creating their entries and on other occasions involve merging or even removal of existing documents. The latter can happen because in our business domain, both users and devices can have multiple identifiers and there is no single identifier for either that is leveraged by all input data sources. Once the entities are resolved, the next phase of this flink job is to process all the events within the payload, the processing of which can result in change in state of the user or the device involved. Rather than updating their states directly, it determines the change in state and publishes them to Kafka to be used by another downstream service to update entities in bulk. We are able to determine the change in state as the job relies on RocksDB as the source of truth. Thus RocksDB not only helps us cut down our database reads by more than half, more importantly, it allows us to leverage bulk writes to databases.
Reaction Streaming
The final service in our pipeline is a relatively simple service that consumes MongoDB update requests from Kafka and applies them in bulk, thereby greatly increasing the write throughput of our database clusters. With RocksDB serving as a source of truth, we can leverage full non-blocking and asynchronous I/O to do our updates which helps us greatly improve our efficiency of writes. Not only do we do more writing but we’re able to do them with far fewer resources! We did have to spend some time building a buffering mechanism that ensures that any entity has only one update in-flight at any given time, without which the order of write operations can never be guaranteed.
MoEngage’s real-time ingestion infrastructure helps brands drive more ROI from their engagement, retention, and monetization campaigns
How Do We Ensure Resiliency Of Our Systems?
Splitting our ingestion layer into three different jobs helped us achieve the efficiency that we wanted but this comes at the cost of greater chances of failures. Any one of the services could go down due to change in code or stability issues within our cloud. Checkpoints can help us avoid re-processing all of the data in our messaging layers but it doesn’t eliminate the chance of duplicate data processing. This is why it was critical to ensure that each service was idempotent.
Reaction streaming was designed to support only a select set of write operations – set, unset, adding to a set and removing from a set. Any client intending to use this service would need to leverage one or more of these operations. This set of four operations have one thing in common – the repeated application of any of these on a document will ultimately produce the same result.
API Unification Layer & Action Streaming both rely on Kafka transactions to ensure that even if data gets processed multiple times, it isn’t made available to downstream services until the checkpoint completes. Care is also taken to ensure that all time based properties have stable values despite restarts and ensuring that no record older than these times ever gets re-processed.
Learnings and Key Takeaways
While Flink does offer great features that do indeed work at our scale, its feature set is often lacking in various aspects which result in more developer effort than planned. Some of these weaknesses aren’t often well documented, if at all, while some features require quite a bit of experimentation to get things right.
- Its quite common for various flink libraries to break backward compatibility which forces developers to constantly rework their code if they wish to leverage newer features
- Flink also supports various useful features such as auto-scaling, exactly once semantics, checkpoints which require a lot of experimenting to get right with little guidance on picking how to pick the right set of configurations. That said, the community is very very responsive and we’re thankful for their help in our journey
- Integration testing of flink jobs is virtually impossible given how resource intensive it is. Unit testing is possible but is rather cumbersome. We would suggest developers to keep almost no logic in the flink operators themselves and merely rely on them for data partitioning and state management
- Schema evolution doesn’t work when the classes leverage generics, which is almost always the case. This forced us to spend time on writing our own serde logic. What also caught us off-guard was that even newer Java features such as Optional can cause schema evolution to not work
- We wanted to leverage the broadcast operator for simplifying configuration management. However since input streams from other sources could fire independently, we ended up not using this solution. It would be good to have a signaling mechanism among operators.
- Over the years, we’ve hit quite a few stability issues when working with Zookeeper and Kafka which turned out to be legitimate bugs in their codebase. Most of them have now been fixed but we’ve had to face a lot of production issues and built quick workarounds in the meantime.
MoEngage constantly strives to make improvements to the platform that helps brands deliver seamless experiences to their customers
Future Enhancements
There are several enhancements that we plan to work on in the coming months, some of which are:
- We’re now at a stage where we’re convinced that we’ve hit the limits of MongoDB and, after a few years, will need to explore an alternate store for user and device properties that can support much higher write throughput while MongoDB itself would be leveraged for its indexes
- Flink’s checkpoint mechanism requires the job to be a directed acyclic graph. This makes it impossible to exchange state within sub-task of the same operators. While this is very well documented, it’s a feature that we need, and we will explore Flink’s sibling project Stateful Functions, which doesn’t have this limitation
- Flink’s recently released Kubernetes operator can handle the entire application lifecycle, which gives better control over checkpoints and savepoints than our own in-house developed solution, and we plan to switch it someday
- The use of Kafka makes it difficult to implement rate-limiting policies as we have thousands of customers whose data is distributed among the partitions of a topic and Kafka itself can’t support one topic per client at our scale. We will explore alternate pub-sub layers, such as Pulsar and Pravega, that offer greater flexibility in this regard
- We considered leveraging OpenTelemetry for end-to-end metrics and log-based monitoring and distributed tracing across services; however, it has only recently moved out of alpha. We will explore this further as an end-to-end monitoring solution
Conclusion
We set out to ensure real time ingestion of our clients’ data at all times at a scale which exposes the flaws of the best open source frameworks. These are the numbers we were able to achieve.
93% of the time, the data is available to the customers within 5 seconds.
It was a great challenge to be able to learn and become adept at multiple languages and frameworks and we’ve thoroughly enjoyed knocking them off one by one! If you’re interested in solving similar problems, check out our current openings in the Engineering team at MoEngage!






